The MyST Children’s Conversational Speech Corpus
Characteristics of the MyST Corpus
The current release (v0.4.0) of the Corpus consists of 393 hours of children’s speech collected from 1,371 third, fourth, and fifth grade students. Students conversed with a virtual science tutor in 8 areas of science, resulting in a total of 10,496 student sessions and a total of 228,874 utterances. Roughly 45% of the utterances have been transcribed at the word level.
Partitioning of Data for Development and Evaluation
For the convenience of the ASR community, we partitioned and structured the corpus upfront into training, development and test sets. These partitions were generated ensuring that they reasonably represent each of the science module in MyST and that each student is present in only one of the three partitions. These three data sets are in three separate directories in the corpus release.
Data Collection
The MyST corpus was collected in 2 stages, Phase I (2008-2011); and Phase II (2013 – 2018). The file structure for both corpora is corpora/myst/data/<partition>/<student_id>/<session_id>/<session_id>.<file-extension>
Phase I
The Phase I corpus contains sessions from students in grades 3-5. All sessions have been transcribed. Students interacted with the virtual tutor during 16 15-20 minutes sessions in 4 areas of science:
- ME – Magnetism and Electricity
- MS – Mixtures and Solutions
- VB – Variables
- WA – Water
A <session_id> is represented as <corpus>_<student_id>_<date>_<time>_<module>_<investigation>.<part>. The <student_id> is a 3-digit school code and a 3-digit student number. example: myst_990507_2010-04-02_00-00-00_WA_2.3
We did not capture the time for Phase I, so all the times are 00-00-00
| Number of Students: | 421 | ||
| Number of Sessions: | 1,509 | (102 | hours) |
| Transcribed Sessions: | 1,509 | (102 | hours) |
| Untranscribed Sessions: | 0 | (0 | hours) |
There was no attempt to have any individual student cover all of the parts for a module. The focus of the collection was to get a wide variety of students rather than try to get complete coverage of material for individual students.
Phase II
The Phase II corpus contains sessions from students in grades 4-5. It uses 5 modules, with an average of 10 parts each
- EE – Energy and Electromagnetism
- MX – Mixtures
- SMP – Sun, Moon and Planets
- SRL – Soil, Rocks and Landforms
- LS – Living Systems
Again, the student_id is a 3-digit school code and a 3-digit student number and the session ids are encoded similarly.
| Number of Students: | 950 | ||
| Number of Sessions: | 8,987 | (291 | hours) |
| Transcribed Sessions: | 1,426 | (95 | hours) |
| Untranscribed Sessions: | 3,711 | (196 | hours) |
Data Cleanup and Pre-processing
We did a pass over the corpus to clean up various types of errors that could be identified using statistics on the underlying audio and potentially erroneous data collection.
- Session Quality
Bad—empty or corrupted sessions were removed using simple heuristics and based on missing data. - Session Length
Sessions that were less than a certain minimal threshold (< 10 minutes long), or longer than a certain maximum threshold (> 1 hour long) were inspected and corrected or removed. - Missing audio files
Sessions that were missing audio files for a significant number of utterances were deleted. - Missing log files
Sessions that were missing the raw log files were removed. - Audio Quality
All utterances were processed to identify all possible unacceptable recordings and were removed from the database. We performed the following checks. - Clipping Rate
If the there was a significant number of frames (exceeding a certain threshold) that were clipped, we removed or marked the audio file. We removed them if it impacted more than a certain fraction of utterances in a session. In which case we also removed the session from the release. If only a small amount of files had large fraction of clipping, we tagged them in a report file, so that the users can determine whether to include or exclude that data from their study. - Silence
Sometimes there are significant amounts of leading and trailing silence in the audio files. We trimmed all such silence. We did not, however, remove or compress silence that occured within an utterance. - Background Noise
Utterances with a significant amount of noise or cross talk were removed. This was only possible for the cases that were transcribed, or fell in the fraction of sample utterances that we manually verified.
Transcription Quality
We fixed obvious spelling errors in the transcriptions. We tried to retain explicitly mispronounced words as much as possible.
Updated Pronunciation Dictionary
We also make available an updated pronunciation dictionary. We used CMU’s pronunciation dictionary as a starting point and added words that were novel to this corpus.
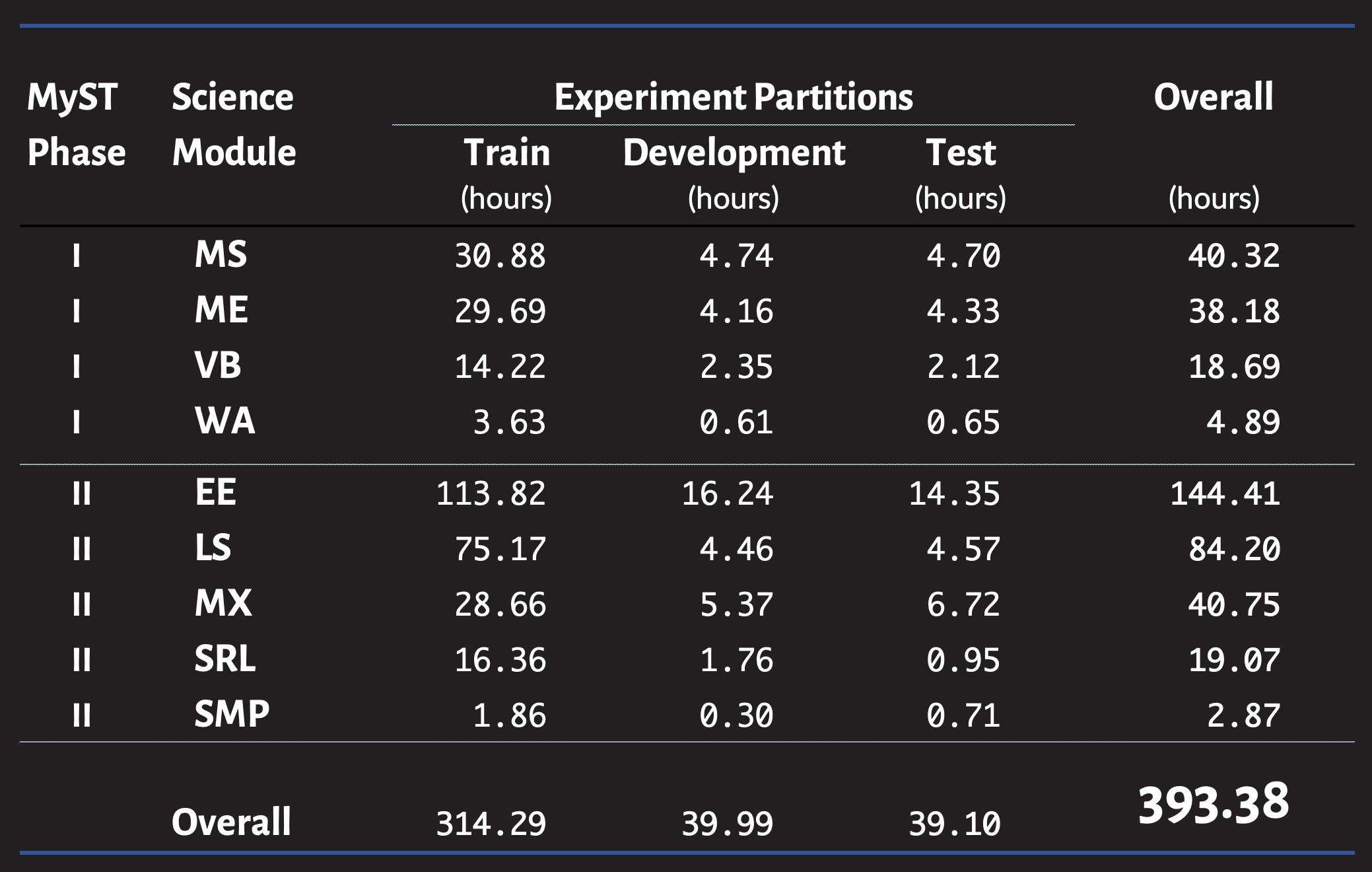
Experiment Partitions
The table below lists the distribution of audio data (in hours of audio) that are present in each of the train, development and test partitions. It shows them aggregated over each partition, each science module, and the sum total hours for the entire corpus.
How can I contribute to the MyST Corpus
While this is the largest transcribed children’s speech corpus in the world, only less then half of the utterances have been transcribed. We are requesting interested members of the community to contribute to completing the transcriptions. If you are interested, we will define a set of utterances that you can transcribe along with the transcription conventions. – If you are agreeable, we will add your name to the list of people who have contributed to the corpus. In order to make the contribution, you would need to get access to the GitHub repository with the transcriptions and further information on the logistics of the contribution process. Please use this form to send us your GitHub username and we will add you to the repository as a collaborator.